Mit dem Release des SQL Servers 2016 von Microsoft wurde PolyBase als ein neues Feature eingeführt. Jedoch ist diese Funktionalität nicht neu; sie war bereits in der 2012er Version des Microsoft Analytics Platform System (APS) verfügbar. In diesem Blogbeitrag finden Sie einen technischen Überblick zu PolyBase.
Im Grunde genommen dient PolyBase als Brücke zwischen dem SQL Server und semi-strukturierten/nicht-strukturierten externen Datenquellen wie bspw. Hadoop oder dem Azure Blob Storage. Somit kann man relationale und nicht-relationale Datenbanken (NoSQL) gleichzeitig abgefragen. Auch das Importieren und Exportieren von Daten von und nach externen Datenbanken wird dadurch ermöglicht. Ferner können bestehende BI Tools, die bereits auf den SQL Server zurückgreifen zusätzlich auf die externen Datenquellen zugreifen.
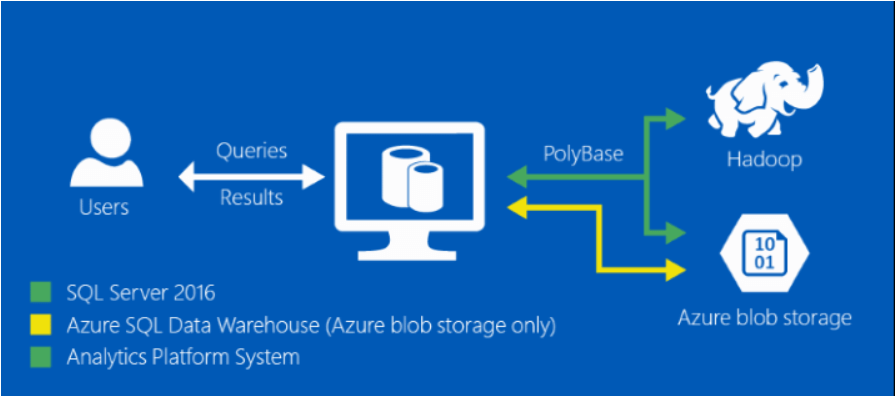
Ein wesentlicher Vorteil besteht darin, dass PolyBase keine zusätzlichen Softwareinstallationen auf den externen Datenquellen benötigt. Außerdem kann man Abfragen in T-SQL schreiben und im SQL Server Management Studio ausführen. Die Befehle werden im Hintergrund in die entsprechende Syntax der externen Datenquelle übersetzt und dort ausgeführt. Somit ist eine Einarbeitung in die jeweilige spezifische Syntax der externen Datenquelle für den Anwender nicht notwendig.
Eine mögliche Vorgehensweise der Installation von PolyBase auf dem SQL Server bietet Microsoft an.
Polybase Scale-Out Groups
Eine einfache SQL Server Instanz mit einer Polybase Engine kann zu Performance Beeinträchtigungen führen, wenn große Datenmengen aus externen Datenbanken abgefragt werden. Daher gestattet das Group Feature mehrere SQL Server Instanzen zu einem gemeinsamen Cluster zu vereinen, damit Abfragen mit großen Datenmengen aus externen Datenbanken besser skaliert werden und somit zur Performanceoptimierung beisteuern können. Die folgende Abbildung stellt hierzu die Vorgehensweise dar:
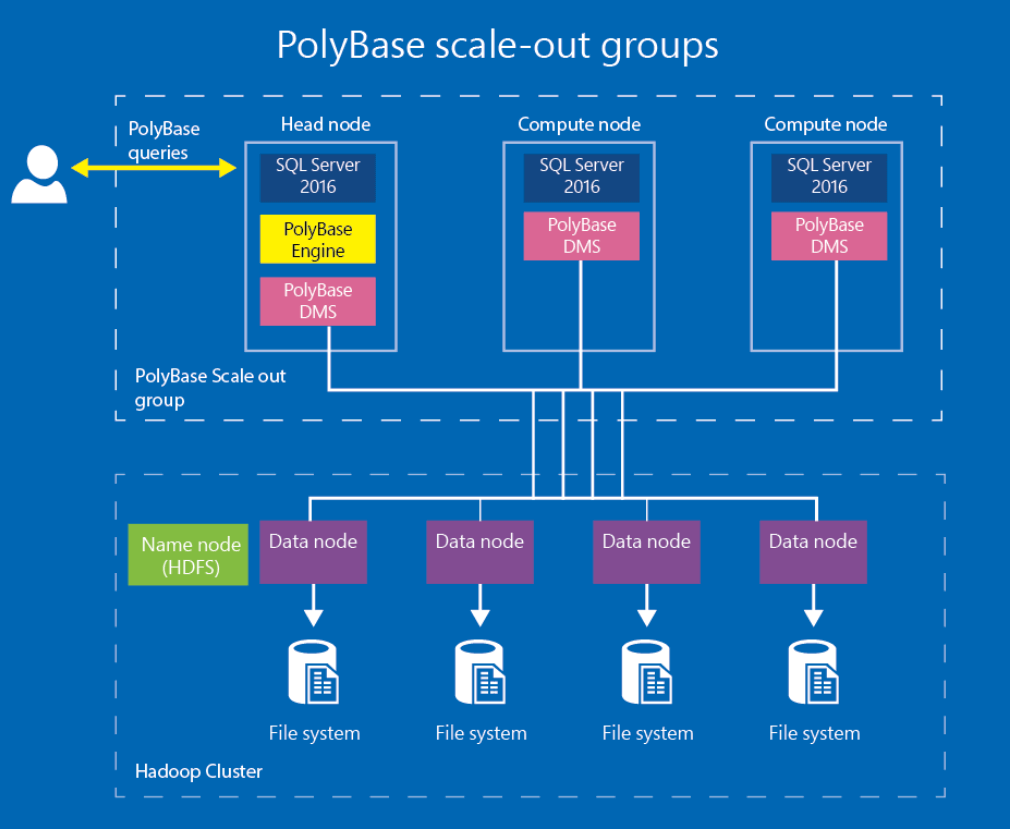
In jedem Cluster kann es nur einen Head Node und mindestens einen Compute Node geben. Diese Hierarchie entspricht der Aufteilung in Hadoop Clustern, in denen ein Name Node und mindestens ein Data Node existiert.
Der Head Node beinhaltet die SQL Server Instanz, auf der man die Abfragen ausführt. Dabei werden die Bereiche der Abfrage, die externe Datenquellen beinhalten, auf die PolyBase Engine geschoben. Die Engine übersetzt die Abfrage und erzeugt Query Pläne anhand der erstellen Statistiken auf den externen Tabellen. Des Weiteren verteilt die Engine die Aufgaben an den Data Movement Service (DMS) weiter, der auch auf den Compute Nodes installiert ist.
Der Compute Node umfasst die SQL Server Instanzen, die beim Skalieren der großen Datenmengen Abfragen unterstützen sollen. Der PolyBase DMS transferiert Daten zwischen den externen Datenquellen und dem SQL Server und zwischen dem Head Node und den Compute Nodes.
Eine genaue Vorgehensweise der Konfiguration von PolyBase Server Clustern auf dem SQL Server bietet Microsoft an:
Hier ein Beispiel zum Anlegen einer externen Datenquelle mit Datenformat und Tabelle:

Die externe Tabelle kann dann mit SELECT * FROM Table_01 abgefragt werden.
Weitere Beispiele zum Erstellen von externen Datenquellen und Tabellen findet man bspw. unter:
https://docs.microsoft.com/en-us/sql/relational-databases/polybase/polybase-t-sql-objects
https://docs.microsoft.com/en-us/sql/relational-databases/polybase/polybase-queries
Bei weiteren Fragen zu diesem spannenden Thema kontaktieren Sie uns gerne.