
Microsoft Fabric Data Agents: Agentic Apps auf Microsoft Fabric
Microsoft Fabric Data Agents: Agentic Apps auf Microsoft Fabric Data Agents: Warum agentische Anwendungen auf Microsoft Fabric die Zukunft sind…

Erfahrene Datenbank-Entwickler kennen die Tücken des Datentyps „DateTime„. Doch viele Anfänger stolpern über die Hürden, die dieses sehr spezielle Konstrukt mit sich bringt. In diesem Artikel beschreibe ich die grundsätzlichen Kriterien für die Entscheidung für oder gegen einen bestimmten Datentyp. Außerdem zeige ich in zwei Beispielen Situationen, in denen die Wahl der „falschen“ Architektur sicher bereut wird und zu unerwarteten Ergebnissen führt.
In einer Datenbank bekommt jede Spalte eines Objektes, bspw. einer Tabelle, einen Datentyp zugewiesen. Dieser gibt an, welcher Art die Informationen sind, die in diesem Feld gespeichert werden sollen. Üblicherweise unterscheidet jedes Datenbankmanagementsystem, so auch der SQL Server von Microsoft, verschiedene Gruppen von Datentypen. Innerhalb einer Gruppe gibt es dann mehrere Ausprägungen mit leichten Unterschieden.
Ganzzahlen: bit, tinyint, smallint, int, bigint
Währungstypen: smallmoney, money
feste Genauigkeit: numeric, decimal
Die Datentypen unterscheiden sich in der Wertemenge (und damit auch dem Platzbedarf)
float, real
Die Datentypen unterscheiden sich in der Genauigkeit (und damit auch dem Platzbedarf)
date, datetimeoffset, datetime2, smalldatetime, datetime, time
Die Datentypen unterscheiden sich in der Genauigkeit (und damit auch dem Platzbedarf) und in der Frage, ob ein reines Datum, eine reine Uhrzeit oder beides gespeichert wird
Zeichenfolgen: char, varchar, text
Unicode-Zeichenfolgen: nchar, nvarchar, ntext
Die Datentypen unterschieden sich in der möglichen Inhaltsgröße (und damit dem Speicherbedarf). Unicode-Zeichenfolge können auch Elemente aus dem UTF-16-Umfang enthalten. Variable Datentypen sind auf Speicherplatz optimiert.
binary, varbinary, image
Mit diesen Datentypen lassen sich auch Bilder, Word-Dateien oder MP3s direkt in der Datenbank speichern.
Räumliche Geometrietypen, Räumliche Geografietypen, Cursor, uniqueidentifier, sql_variant, xml, Tabelle, rowversion, hierarchyid
Mit diesen Datentypen kann der SQL Server u.a. sogar zeichnen, eine XML-Struktur lesen und schreiben…
Mit der Wahl eines Datentyps legt man fest, was später in diesem Feld gespeichert werden kann. Eine Fehleinschätzung lässt sich später nicht mehr oder nur mit enormen Aufwand korrigieren. Daher gilt es typische Fehler zu vermeiden:
Kennt man die potenziellen Inhalte vorher und wählt den Datentyp dann unpassend groß, verschenkt man Speicherplatz und opfert unnötigerweise Verarbeitungs- und Abfragegeschwindigkeit. Es macht bspw. keinen Sinn eine internationale Telefonvorwahl (aktuell maximal 5-stellig) als „nchar(250)“ zu speichern.
Beschränkt man die Größe eines Datentyps über ein vertretbares Maß hinaus, werden sich nicht alle Inhalte später speichern lassen. Unten zeige ich zwei Beispiele, wie eine derartige Architektur zu Syntaxfehlern oder kaum zu findenden Fehlerverhalten führt.
Mit welchem Datentyp speichert man das Alter eines Käufers? SmallInt? TinyInt?… Nein, man speichert es gar nicht, denn es ändert sich ja jährlich! Statt dessen sollte man das Geburtsdatum sichern und das Alter zur Laufzeit aus diesem berechnen.
Und welchen Datentyp nutzt man um eine Hausnummer zu speichern? SmallInt? Oder doch lieber BigInt? Bitte weder noch, denn es gibt Hausnummern wie „176c“, diese sind alphanumerisch und passen somit nicht in einen numerischen Typ.
Doch selbst wenn man sich für einen augenscheinlich passenden Datentyp entschieden hat, droht noch Ungemach. Ganz so einfach ist es nämlich leider nicht. Das folgende Beispiel verdeutlicht dies:
CREATE TABLE [#DatentypDemo](
[ZeitstempelDT] [DATETIME] NOT NULL
, [ZeitstempelDT2] [DATETIME2] NOT NULL
) ON [PRIMARY]
GO
INSERT INTO [#DatentypDemo] ([ZeitstempelDT], [ZeitstempelDT2])
VALUES ('2022-01-01 00:00:01.001', '2022-01-01 00:00:01.001')
,('2022-01-01 00:00:01.002', '2022-01-01 00:00:01.002')
,('2022-01-01 00:00:01.003', '2022-01-01 00:00:01.003')
,('2022-01-01 00:00:01.004', '2022-01-01 00:00:01.004')
,('2024-12-31 23:59:59.996', '2024-12-31 23:59:59.996')
,('2024-12-31 23:59:59.997', '2024-12-31 23:59:59.997')
,('2024-12-31 23:59:59.998', '2024-12-31 23:59:59.998')
,('2024-12-31 23:59:59.999', '2024-12-31 23:59:59.999')
GO
Dieses kleine Skript legt eine temporäre Tabelle an und fügt acht identische Datumswerte einmal als „DateTime“, einmal als „DateTime2“ ein.
Wenn man jetzt dieses Werte per SELECT mit einem Filterkriterium abfragt, erlebt man eine Überraschung:
SELECT
'DATETIME: Anzahl Datensätze in 2025' AS [Abfrage]
, COUNT(*) AS [Anzahl]
FROM [#DatentypDemo]
WHERE YEAR([ZeitstempelDT]) = '2025'
UNION
SELECT
'DATETIME2: Anzahl Datensätze in 2025'
, COUNT(*) FROM [#DatentypDemo]
WHERE YEAR([ZeitstempelDT2]) = '2025'
GO
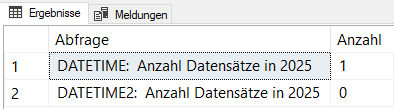
Wie kommt der SQL Server zu dem Ergebnis, dass es in der „DateTime“-Spalte einen Eintrag für das Jahr 2025 gibt? Und wieso ist dies in der „DateTime2“-Spalte nicht der Fall – obwohl doch die Inhalte identisch eingefügt wurden?
Eine weitere Abfrage zeigt, wie dramatisch sich dieses bisher unerklärliche Verhalten entwickeln kann. Es wäre besser sich nicht vorzustellen, dass derartige Effekte bei der Berechnung der Rentenhöhe oder der Festlegung eines Baukredites zum Tragen kommen:
SELECT
'DATETIME: Anzahl Datensätze 2022-01-01 00:00:01.003' AS [Abfrage]
, COUNT(*) AS [Anzahl]
FROM [#DatentypDemo]
WHERE [ZeitstempelDT] = '2022-01-01 00:00:01.003'
UNION
SELECT
'DATETIME2: Anzahl Datensätze 2022-01-01 00:00:01.003'
, COUNT(*)
FROM [#DatentypDemo]
WHERE [ZeitstempelDT2] = '2022-01-01 00:00:01.003'
GO![]()
Auch hier entspricht das Ergebnis der „DateTime2“-Spalte den Erwartungen. Die Anzahl für die „DateTime“-Spalte scheint hingegen beliebig zu sein. Zur Erinnerung: Die beiden Spalten wurden identisch gefüllt. Es gibt jeweils nur genau einen Satz „2022-01-01 00:00:01.003“.
Ein Blick auf die Inhalte der temporären Tabelle entlarvt den Denkfehler jedoch sofort. Die Wahrheit liegt in den Daten:
SELECT * FROM [#DatentypDemo] GO
![]()
Der Datentyp „DateTime“ ist per Definition auf 3 Nachkommastellen beschränkt und kann diese nur in 3-Millisekunden-Sprüngen abspeichern. Somit ist es nicht möglich, einen Wert wie „2022-01-01 00:00:01.001“ einzufügen. Er wird „abgerundet“ auf die Millisekunden „000“. Der Wert „2022-01-01 00:00:01.002“ hingegen wird aufgerundet auf die Millisekunden „003“. So kommen die eigenartigen Werte in der „DateTime“-Spalte zustande. Die „DateTime2“-Spalte unterliegt diesen Manipulationen nicht! Somit sind die Filterergebnisse des SQL Servers plausibel…
Ein weiteres Beispiel suggeriert einen Rechenfehler in einer T-SQL-Abfrage:
DECLARE @varDateTime2 AS DATETIME2(3)
DECLARE @varDateTime AS DATETIMESET @varDateTime2 = '2022-10-17 11:23:32.666000'
SET @varDateTime = '2022-10-17 11:23:32.666'SELECT
'Millisekunden' AS [ ]
, DATEPART(millisecond, @varDateTime2) AS [DateTime2]
, DATEPART(millisecond, @varDateTime) AS [DateTime]
UNION
SELECT
'Mikrosekunden'
, DATEPART(microsecond, @varDateTime2)
, DATEPART(microsecond, @varDateTime)
UNION
SELECT
'Nanosekunden'
, DATEPART(nanosecond, @varDateTime2)
, DATEPART(nanosecond, @varDateTime)
ORDER BY [DateTime2]
![]()
Bei der Zuweisung einer Zeitangabe mit drei Nachkommastellen an einen „DateTime“-Datentyp wird unter Umständen gerundet – den Effekt haben wir oben nachgewiesen. Doch wie ist zu erklären, dass die Mikrosekunden und Nanosekunden in den hinteren Stellen keine Nullen aufweisen? Wer ein bisschen mit den Zahlen (Zeile 4+5) spielt, wird schnell merken, dass der SQL Server einfach die letzte Stelle der Millisekundenangabe des „DateTime“-Datentyps fortschreibt und damit den Wert des Inhaltes verändert.
Der Effekt verwundert – ist aber nicht außerhalb der Spezifikationen. Per Definition sind „DateTime“-Datentypen nur für Inhalte mit maximal drei Nachkommastellen geeignet. Eine Abfrage auf Mikrosekunden ist also außerhalb des vorgesehenen Einsatzbereichs. Wer die Genauigkeit bis runter zu Nanosekunden benötigt, sollte daher zwingend zum Datentyp „DateTime2“ greifen!
[/vc_column_text]



