
Sommerloch in der IT: Wie Microsoft Fabric Licht in die Ressourcenplanung bringt
Sommerloch in der IT-Ressourcenplanung Wenn die halbe Firma am Strand liegt und die andere Hälfte Wunder vollbringen soll, beginnt in…
Nach den Veröffentlichungen “Das kniffelige Teilsummenproblem mit T-SQL gelöst” und “Wie löst man mit SQL einen Zauberwürfel” von Torsten Ahlemeyer in der „Informatik Aktuell“, gesellt sich nun mit Emil Vinčazović ein weiterer Kollege als Fachautor hinzu. Er veröffentlicht seinen ersten Artikel über das Thema “Betrugserkennung per Python mit KI”. Auch auf den diesjährigen IT-Tagen wird er zu dem Gebiet der Informatik referieren. In dem Artikel erklärt der IT-Berater unter anderem, wie man die Daten bearbeiten muss, um bestmögliche Resultate in der Betrugserkennung zu erzielen.
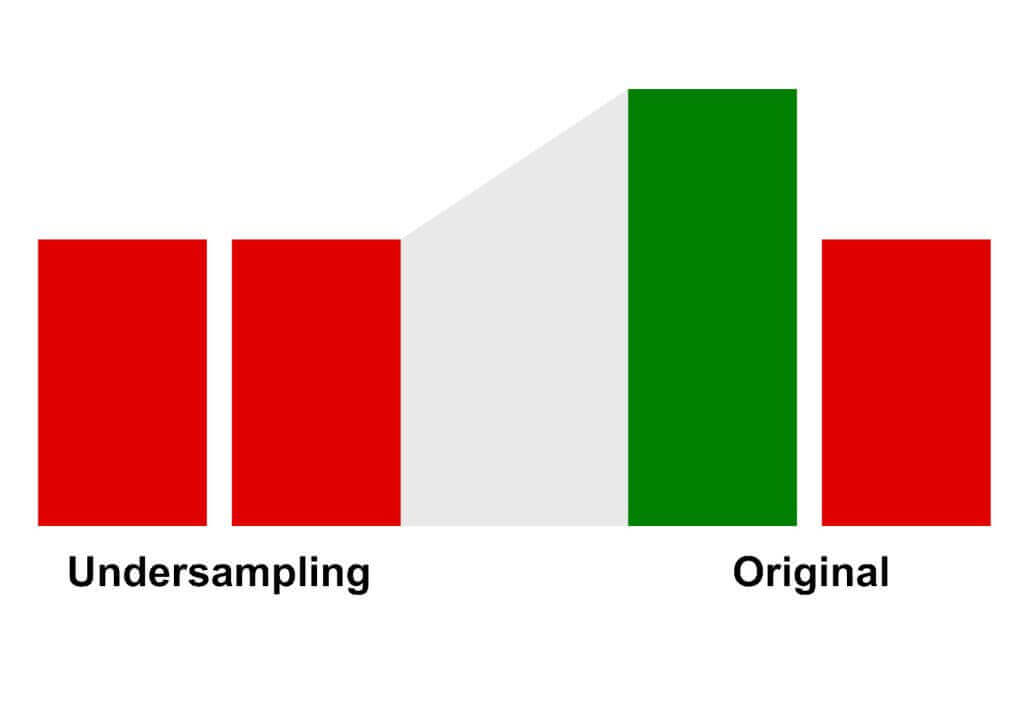
Da es in Geschäftsprozessen sehr wenige Betrugsdaten gibt, müssen die Daten geschickt an die jeweilige Verwendung angepasst werden, um bestmögliche Ergebnisse zu erzielen. Das größte Hindernis an der Sache ist das Problem des unbalancierten Datensatzes. Dieses Problem führt zu fehlerhaften und verzerrten Ergebnissen. Die Lösung dieser Aufgabe liegt im Umstrukturieren der Daten. Möglich sind das Over- und das Undersampling, sowie die Kombination beider.
![]()
Von allen sogenannten „Samplingtechniken“, gibt es viele verschiedene Methoden mit Vor- und Nachteilen. Hier wurden das SMOTE- (Synthetic Minority Oversampling Technique) und das NearMiss-Verfahren verwendet.
Nachdem die Daten manipuliert und in Test- und Trainingsdaten unterteilt wurden, werden sie von verschiedenen Machine Learning Algorithmen analysiert, umso die bestmögliche Vorgehensweise für den Datensatz zu finden. Hier wurden der RandomForest, der XGBoost und die Support-Vector-Machine miteinander verglichen. Je nachdem für welchen Anwendungsfall man die Betrugserkennung anwenden will, eignet sich eine andere Metrik zur Auswertung am besten. Will man beispielsweise möglichst viele Datenpunkte richtig klassifizieren, eignet sich die Accuracy Metrik am besten.
In der Betrugserkennung per Python mit KI spielen viele Faktoren eine Rolle, um die Ergebnisse zu verbessern. Vor allem die Datenmanipulation trägt einen großen Teil dazu bei, die Qualität der Ergebnisse anzuheben. Den ausführlichen Artikel von Emil Vinčazović inklusive einer detaillierteren Erklärung der Analyse sowie die Ergebnisse findet man unter folgendem Link.




