
Sommerloch in der IT: Wie Microsoft Fabric Licht in die Ressourcenplanung bringt
Sommerloch in der IT-Ressourcenplanung Wenn die halbe Firma am Strand liegt und die andere Hälfte Wunder vollbringen soll, beginnt in…

In modernen Unternehmen fallen täglich große Datenmengen aus verschiedenen internen und externen Quellen an. Um auf Basis dieser Daten geschäftskritische Entscheidungen treffen zu können, müssen die Daten in ein einheitliches Format gebracht werden. Dieser Prozess wird auch als ETL-Prozess bezeichnet und gliedert sich in die folgenden drei Schritte. Extract (Extraktion der Rohdaten aus verschiedenen Quellen), Transform (Überführung der Rohdaten in ein einheitliches Format) und Load (zentrale Bereitstellung der Daten). In diesem Beitrag werde ich Schritt für Schritt erläutern, wie ein ETL in Azure Synapse Analytics implementiert werden kann.
Warum immer mehr Unternehmen den Weg in die Cloud finden, zeigt eine Reihe von Vorteilen, die die Cloud bietet:
Azure Synapse ist eine Cloud-basierte Datenanalyseplattform von Microsoft, die Datenverarbeitungs- und Analysedienste in einer einzigen Umgebung vereint. Sie ermöglicht es Unternehmen, große Mengen strukturierter und unstrukturierter Daten aus verschiedenen Quellen zu sammeln, zu speichern, zu verarbeiten und zu analysieren. In diesem Blogbeitrag werde ich den ETL-Prozess in Azure Synapse Analytics (Extract, Transform, Load) in Synapse anhand einer Azure SQL-Datenbank erläutern. In diesem Beispiel arbeite ich mit den Beispieldaten der Azure SQL Datenbank, die die Geschäftsdaten eines virtuellen Fahrradladens repräsentieren.
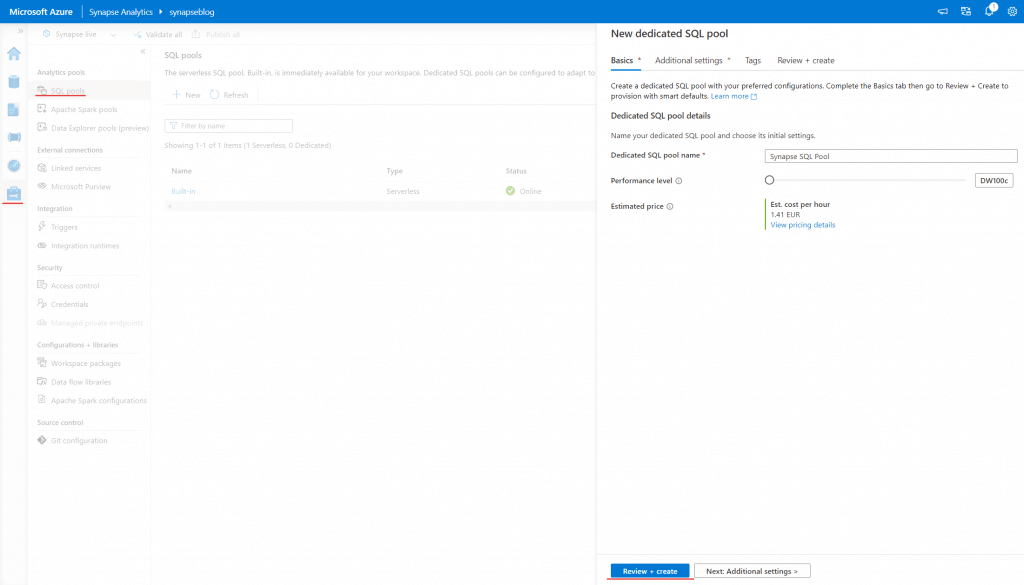
Um einen ETL-Prozess in Azure Synapse Analytics zu implementieren, müssen wir zunächst einen Dedicated SQL Pool einrichten. Der Dedicated SQL Pool (früher auch SQL Datawarehouse genannt) ist ein sogenanntes Massively Parallel Processing oder kurz MPP. Dabei handelt es sich um eine moderne Datenbankarchitektur, bei der eine große Anzahl von Prozessoren parallel arbeitet, um die Daten in kleinere Teile aufzuteilen und diese gleichzeitig zu verarbeiten. In diesem SQL-Pool werden wir später unsere Daten speichern.
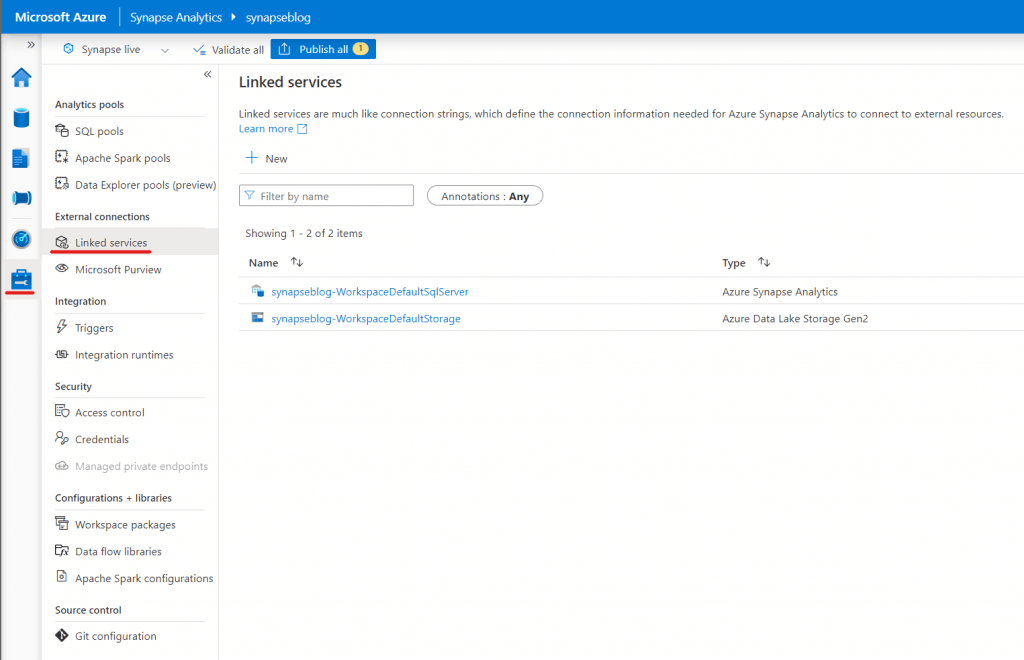
Nun müssen wir in Synapse eine Verbindung zu unserer Azure Datenbank herstellen. Dazu klicken wir in der linken Menüleiste auf Manage und dann auf „Linked services„. Wenn wir dann auf „New“ klicken, öffnet sich ein Menü, in dem wir auswählen können, mit welcher externen Datenquelle wir uns verbinden möchten. Für unser Beispiel wählen wir „Azure SQL Database“.
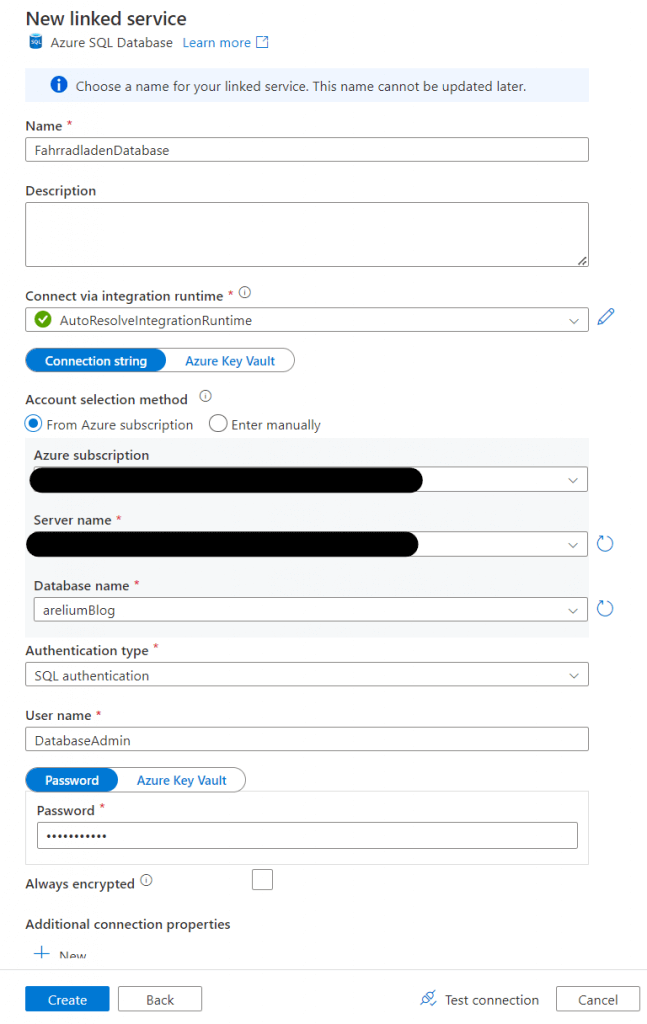
Im nächsten Fenster können wir die Anmeldedaten für unsere SQL Datenbank angeben. Dazu muss die Azure Subscription der Datenbank angegeben werden, sowie der Servername und die gewünschte Art der Authentifizierung. Für dieses Beispiel habe ich die SQL Authentication gewählt, bei der man sich mit einem Benutzernamen und einem Passwort anmeldet. Nun könnt ihr unten rechts auf den Button „Test Connection“ klicken, um zu testen, ob die Verbindung erfolgreich hergestellt werden kann. Ist dies der Fall, könnt ihr auf den „Create Button“ klicken, um die Verbindung zu erstellen.
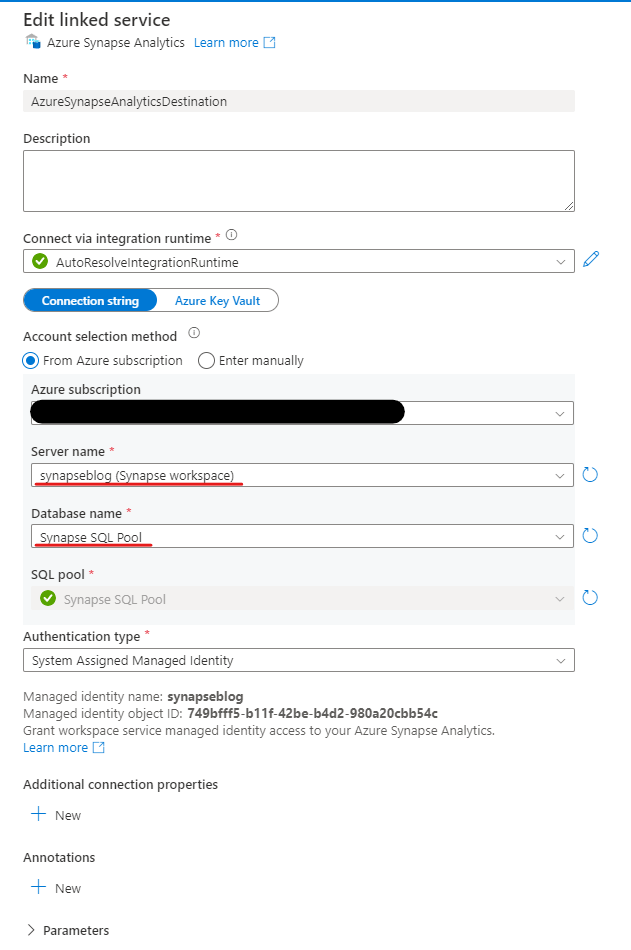
Auf die gleiche Weise können wir nun eine Verbindung zu unserem soeben erstellten SQL-Pool herstellen. Dazu erstellen wir wieder einen neuen Linked Service, wählen aber diesmal „Azure Synapse Analytics“ aus der Liste der möglichen Verbindungen aus. Unter „Azure subscription“ wählen wir wieder unsere Subscription und unter „Server name“ unseren Synapse Workspace aus, in den wir die Daten schreiben wollen. Bei „SQL Pool“ sollte automatisch unser gerade angelegter Dedicated SQL Pool erscheinen. Unter „Authentication Type“ wählen wir nun die Option „System Assigned Managed Identity„. Dabei handelt es sich um einen Mechanismus in Microsoft Azure, mit dem Ressourcen innerhalb eines Azure Service eine Identität erhalten können. Diese Identität kann verwendet werden, um sicher auf andere Azure Ressourcen zuzugreifen, ohne Anmeldeinformationen wie Benutzername und Passwort einbinden zu müssen.
Nun können wir wieder mit dem „Test connection Button“ testen, ob die Verbindung erfolgreich war. Ist dies der Fall, können wir wieder auf Create klicken, um den Linked Service zu erstellen. Nachdem der Linked Service erstellt wurde, kehren wir zum Ausgangsbildschirm zurück und können im linken Menü den Punkt „Integrate“ und dann das Plus-Symbol auswählen, um eine neue „Copy Data Task“ zu erstellen.
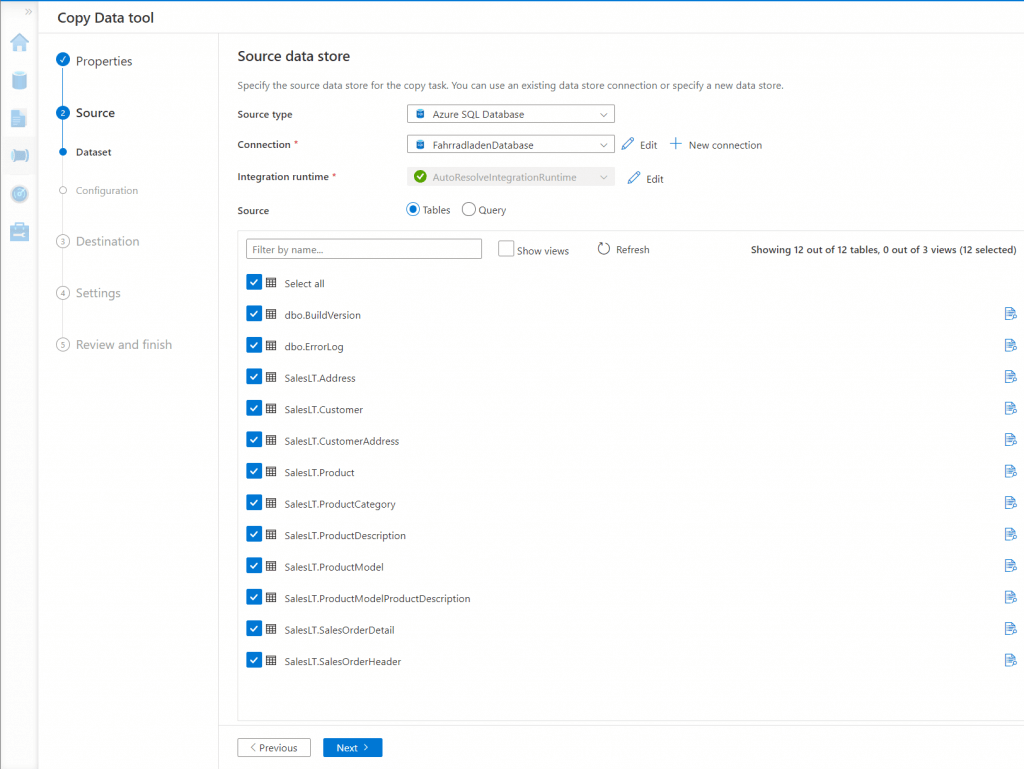
Im folgenden Assistenten können wir im zweiten Menüpunkt die Quelle angeben, aus der die Daten kopiert werden sollen. Dazu geben wir unter „Source type“ wieder „Azure SQL Database“ an und wählen unter „Connection“ unseren zuvor erstellten „Linked service“ aus. Wenn die Verbindung zur Datenbank erfolgreich war, werden nun im unteren Fenster alle Tabellen der Datenbank aufgelistet. Hier wähle ich nun alle Tabellen aus, die ich aus der Datenbank in Synapse importieren möchte. Auf der nächsten Seite kann nun unser zuvor erstellter Azure Synapse Linked Service als Ziel für unsere Daten ausgewählt werden.
Unter dem Punkt Dataset können nun die Tabellen ausgewählt werden, in die die Daten geschrieben werden sollen. Standardmäßig legt Synapse hier automatisch Tabellen im Ziel an, die genau so heißen wie in der Datenquelle und die gleichen Spaltentypen haben. Unter dem Punkt „Konfiguration“ können nun die einzelnen Spalten aufeinander abgebildet werden. Auch hier legt Synapse automatisch die gleichen Spalten wie in der Quelltabelle an und mappt die passenden Spalten aufeinander. Wichtig ist hier, dass wir die Option „Type conversion“ deaktivieren. Nachdem wir dies getan haben, können wir mit dem „Next Button“ zum „Settings“-Bildschirm gelangen.
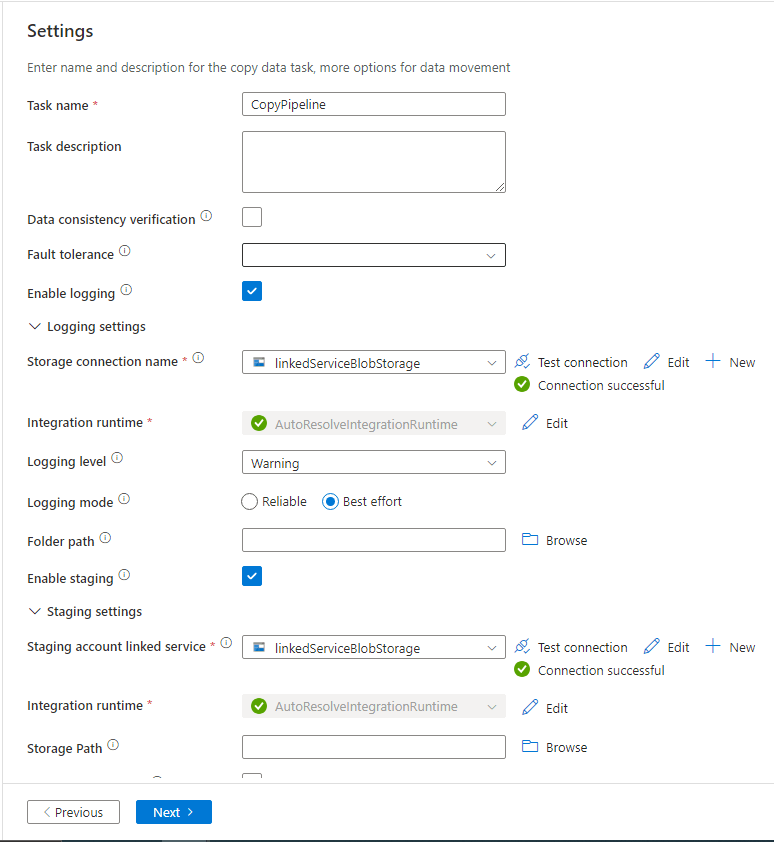
Auf diesem Bildschirm kann unter anderem die Kopiermethode ausgewählt werden, mit der die Daten in die Quelle kopiert werden sollen. Mit der Option „Data consistency verification“ werden nach dem Import der Daten zusätzliche Überprüfungsfunktionen angewendet, um sicherzustellen, dass alle Daten erfolgreich kopiert wurden. Unter anderem werden die Dateigrößen und die Anzahl der Zeilen in Quelle und Ziel verglichen. Da wir jedoch als Kopiermethode „Copy command“ gewählt haben, können wir die Option „Data consistency verification“ nicht aktivieren. Unter „Logging settings“ können die Einstellungen für die Protokollierung während des Kopiervorgangs vorgenommen werden. Mit der Option „Storage connection name“ können wir den Linked Service angeben, der die Verbindung zum Storage speichert, in dem die Logdateien gespeichert werden. Wenn ich auf „New“ klicke, öffnet sich ein Fenster, in dem ich die Verbindung zum Storage erstellen kann.
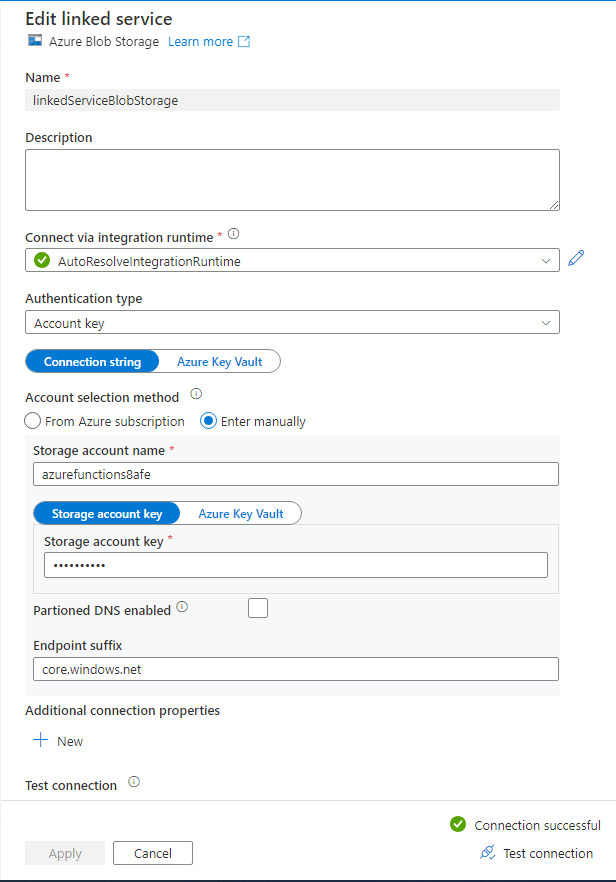
In diesem Fenster wird die Verbindung zu einem Azure Blob Storage definiert. Dazu wähle ich wieder meine Azure Subscription und einen Standard Storage Account meiner Subscription aus. Anschließend teste ich die Verbindung erneut und klicke auf „Create“.
Anschließend aktiviere ich noch die Option „Enable staging“. Dies ist der Storage account in dem die Staging Tabellen gespeichert werden und bei der Option „Storage connection name“ kann der Linked Service für den „Staging Storage“ angegeben werden. Die Staging Area ist ein temporärer Speicherbereich, in dem Daten vorübergehend zwischengespeichert werden, um sie zu transformieren oder zu überprüfen, bevor sie in die endgültige Datenbank geschrieben werden. Für das Staging wähle ich den gleichen Linked Service wie für die Speicherung der Logfiles. Wie oben beschrieben, wähle ich als Kopiermethode „Copy command“. Danach wähle ich „Next“ und komme zum „Review and finish“ Screen, wo wir unsere Einstellungen noch einmal überprüfen können. Danach können wir unser „Copy Data Tool“ starten. Auf dem nächsten Bildschirm können wir sehen, welche Schritte des Deployments gerade ausgeführt werden und ob sie erfolgreich waren.
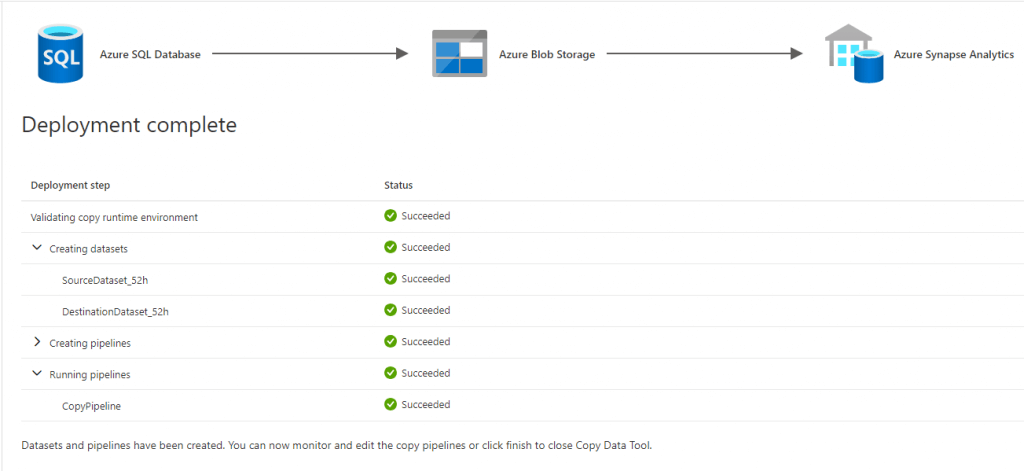
Wenn alle Schritte erfolgreich waren, haben wir unsere Pipeline erstellt, mit der wir Daten von einem Azure SQL Server in unseren Synapse Studio Workspace schreiben können. Der nächste Schritt wäre nun, einen Trigger für die Pipeline zu erstellen. Ein Trigger kann eine Pipeline automatisch starten. Zum Beispiel könnten wir für unsere neue Pipeline einen Trigger einrichten, der die Pipeline automatisch einmal am Tag durchlaufen lässt. Und mit dieser Pipeline können wir einen automatischen ETL-Prozess in Azure Synapse Analytics abbilden.
ETL (Extract, Transform, Load) und ELT (Extract, Load, Transform) sind zwei unterschiedliche Ansätze zur Datenintegration, die in Datenintegrationsprojekten verwendet werden. Der ETL-Transformationsprozess ermöglicht es Unternehmen, Daten zu bereinigen, zu harmonisieren und zu verbessern, um sie für die Verwendung in Data Warehouses oder anderen Zielspeichermedien vorzubereiten. Dazu gehört auch das Entfernen von Dubletten, so dass überflüssige Daten gar nicht erst in den Zielspeicher geladen werden müssen.
Beim ELT hingegen werden die Rohdaten in den Zielspeicher geladen, was das sogenannte Massively Parallel Processing oder kurz MPP ermöglicht. Dabei handelt es sich um eine moderne Architektur, bei der eine große Anzahl von Prozessoren parallel arbeitet. Dadurch werden die Daten in kleinere Teile aufgeteilt und können so gleichzeitig verarbeitet werden. Ein weiterer Vorteil von ELT ist die Flexibilität bei der Datentransformation. Da die Daten direkt in das Zielspeichermedium geladen werden, können Transformationen und Datenverarbeitungsschritte direkt auf die geladenen Daten angewendet werden. Dies ermöglicht es Unternehmen, komplexe Analysen und Berichte direkt auf den Rohdaten durchzuführen, ohne dass separate Transformationsschritte erforderlich sind.
Insgesamt bieten sowohl der ETL- als auch der ELT-Ansatz Vorteile für Datenintegrationsprojekte. Die Wahl zwischen beiden hängt von den spezifischen Anforderungen, der Arbeitslast und den Zielen eines Unternehmens ab. ETL bietet die Möglichkeit, Daten vor dem Laden in das Zielspeichermedium zu transformieren und zu bereinigen. ELT hingegen ermöglicht das direkte Laden von Daten, gefolgt von flexiblen Transformationen auf den Rohdaten. Letztendlich ist es wichtig, den Anwendungsfall sorgfältig zu prüfen, um die beste Lösung für die jeweiligen Anforderungen auszuwählen.




