
Sommerloch in der IT: Wie Microsoft Fabric Licht in die Ressourcenplanung bringt
Sommerloch in der IT-Ressourcenplanung Wenn die halbe Firma am Strand liegt und die andere Hälfte Wunder vollbringen soll, beginnt in…

Das Azure ML Studio ist ein cloudbasiertes ML-Framework. In der von Microsoft zur Verfügung gestellten Umgebung ist es leicht möglich, ML-Pipelines aufzubauen. Die Plattform bietet eine intuitive grafische Oberfläche. Somit ist es auch unerfahrenen Benutzern möglich, ML-Projekte zu erstellen. Das Framework ist sehr flexibel. und vor allem die Auswahl der Verbindungen ist enorm groß. Zusätzlich zu den gängigen Datenquellen wie bswp. dem SQL Server, besteht die Möglichkeit, alle Azure Dienste an das ML-Studio anzubinden. Da es ein Clouddienst ist, besteht außerdem kein Problem mit der Skalierung. Wenn Modelle umfangreicher werden oder die Datenmenge sich erhöht, kann man problemlos die Rechenressourcen der Cloud skalieren. Mehr zur vertikalen und horizontalen Skalierung, gibt es in dem Blogbeitrag zu Azure Synapse Analytics.
Auch der Nachteil der langen Rechenzeit von ML-Modellen wird mit dem Machine Learning Studio sehr gut aufgefangen. Dadurch, dass man verschiedene Compute-Instanzen und sogar Compute-Cluster erstellen kann, wird die Rechenzeit reduziert. Die Kosten steigen jedoch mit gestiegener Rechenpower an.
Machine Learning ist ein Teilgebiet der künstlichen Intelligenz. Es hat die Fähigkeit durch Erfahrung und Beispiele Aufgaben zu erledigen, ohne dass man den Algorithmus explizit auf eine Aufgabe programmiert hat. Die Algorithmen erkennen Muster innerhalb der Daten. Ein einfaches Beispiel des Machine Learning ist die Betrugserkennung bei Bankdaten. Da Machine Learning Algorithmen meist mit strukturierten Daten arbeiten, bieten sich Bankdaten an. Aber auch Vorhersagemodelle lassen sich mit dem Machine Learning wunderbar entwickeln. So könnte beispielsweise die Frage beantwortet werden, wie viel ein Kunde für ein bestimmtes Produkt bereit wäre zu bezahlen.
Prinzipiell wird das Machine Learning in drei Hauptkategorien unterteilt:
Wann welche Kategorie eingesetzt wird ist abhängig von der Datenlage und dem zu analysierenden Vorhaben.
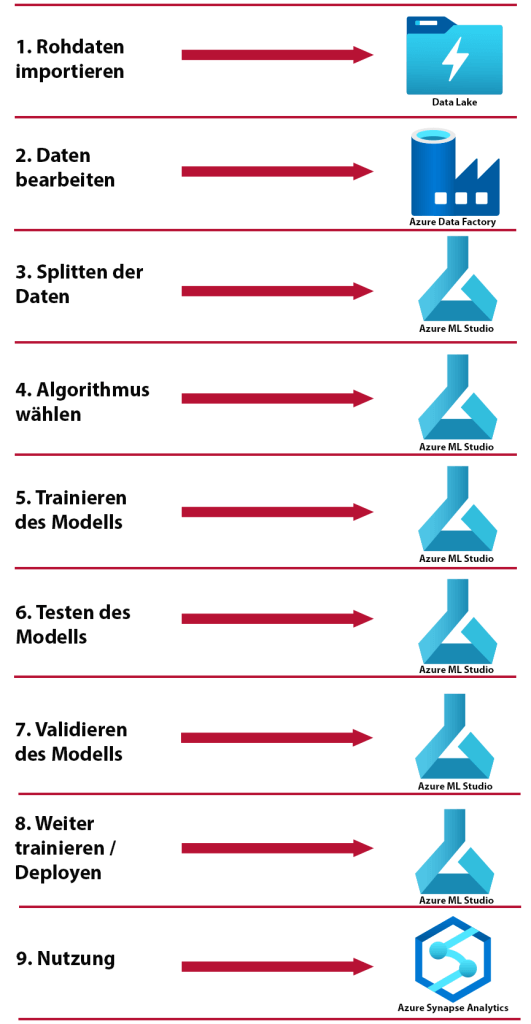
Um die Funktionen des Machine Learning Studios zu verstehen, sollte man sich erst einmal über den Prozess in einer ML-Pipeline Gedanken machen. Im Folgenden wird das Schema eines ML-Prozesses vorgestellt. Zu den Unterpunkten wird die Verbindung zu anderen Azure Ressourcen gezogen. Des Weiteren gibt es einige Erklärungen was während den Schritten passiert.
Im nächsten Schritt müssen die Daten bearbeitet werden. Dies liegt hauptsächlich daran, dass ein ML-Algorithmus nur numerische Werte akzeptiert. Somit muss man die Datentypen anpassen. Außerdem skaliert man die Werte, um Verzerrungen in den Ergebnissen zu minimieren.
Hier besteht die Möglichkeit bei komplizierten Datenbearbeitungen Azure Synapse Analytics Notebooks zu nutzen. Die Azure Data Factory könnte man bspw. bei einfacheren Data Flows nutzen.
Im nächsten Schritt muss der nun saubere Datensatz aufgeteilt werden. Wir benötigen einen Trainings-, einen Test- und einen Validierungsdatensatz.
Das Splitten in verschiedene Datensätze kann theoretisch auch mit den beiden Azure Tools Synapse oder der Data Factory erfolgen. Allerdings kann dies auch im Machine Learning Studio passieren.
Je nach Anwendungsfall sollte man sich im Voraus schon Gedanken über den Algorithmus machen. Handelt es sich beispielsweise um ein Klassifizierungsproblem, fallen einige Algorithmen automatisch raus.
Die endgültige Entscheidung über den Algorithmus sollte im Azure ML Studio getroffen werden. Dort werden viele Hilfestellungen zur Wahl angeboten. Außerdem kann es passieren, dass wenn man einen speziellen Algorithmus nutzen will, dieser in einigen Funktionen des Frameworks nicht gegeben ist.
Das Modell wird mit den in Schritt 3 generierten Trainingsdaten trainiert. Somit „gewöhnen“ wir den Algorithmus an unsere Daten.
Dieser Schritt erfolgt ausschließlich im Azure Machine Learning Studio.
Das trainierte Modell aus Schritt 5, wird mit den in Schritt 3 generierten Testdaten getestet. Die Performancebewertung des Modells steht hierbei im Vordergrund.
Auch diesen Schritt führt man ausschließlich im Azure Machine Learning Studio durch.
Das getestete Modell aus Schritt 6 wird nun mit den in Schritt 3 generierten Validierungsdaten validiert. Damit kann man sicherstellen, dass der Algorithmus nicht zu sehr an die Test- bzw. die Trainingsdaten angepasst ist und eine Verallgemeinerungsfähigkeit noch existiert.
Auch die Validierung des Modells erfolgt im Azure Machine Learning Studio. Dieser Schritt wird teilweise automatisch vom Framework ausgeführt.
Fällt das Ergebnis der Validierung (Schritt 7) positiv aus, sollte man das Modell einsetzen. Sowohl bei einem positivem als auch bei einem negativen Ergebnis muss das Modell weiter trainiert werden. Mit zunehmender Zeit und zusätzlichem Training verbessert sich das Modell.
Das weitere Training findet im ML-Studio statt. Auch das Deployment kann darüber erfolgen.
Die Nutzung des Modells kann überall erfolgen.
Es bietet sich an, das Modell vor allem in die Analysedienste Synapse und die Azure Data Factory einzubinden. Aber auch eine Verbindung zu Power BI oder anderen Microsoft Tools ist einfach möglich.
Im Azure ML Studio gibt es 3 Möglichkeiten eine Pipeline aufzusetzen. Im Folgenden sieht man die drei Varianten.
Das Auto-ML Feature im Azure ML-Studio kann jedermann benutzen. Die Erstellung einer ML-Pipeline erfolgt hier über ein Durchklicken durch ein Menü. Dabei benötigt man kein Vorwissen zur Nutzung. Schritte 1-8 übernimmt das Auto-ML Feature automatisch. Es gilt einige Dinge zu beachten: Zum einen muss man die Verbindung vom Azure ML Studio mit dem richtigen Speicherkonto herstellen können. Zum Anderen ist die Entscheidung wichtig, welche Metriken wichtig für das Ergebnis sind. Des Weiteren sollte man Verständnis für die Metriken und andere Probleme, wie bspw. das Problem des unbalancierten Datensatzes, haben.
Mit dem Designer kann man per Drag-and-Drop eine ML-Pipeline aufsetzen. Allerdings ist es hier problematischer als beim Auto-ML Feature. Da ein ML-Algorithmus nur numerische Werte akzeptiert, muss man die Daten vorher umwandeln. Diese Möglichkeit besteht jedoch im Designer nur bedingt! Somit sollte man die Daten vorher bearbeiten. Hier kommen, wie oben erwähnt, einige andere Azure Produkte zum Einsatz.
Die Notebooks sind die mit Abstand mächtigste Variante im Azure ML Studio um eine ML-Pipeline aufzusetzen. Hier sind dem Anwender keine Grenzen gesetzt. Allerdings benötigt man hier viele Fähigkeiten. Sowohl theoretisches Wissen über die Funktion im ML als auch Programmierkenntnisse in Python sind hier notwendig. Der Vorteil ist, dass man Schritte 1-8 in den Notebooks ohne Probleme durchführen kann. Man benötigt lediglich noch die Verbindung zu einem Speicherkonto in Azure.
Im Folgenden ist eine Tabelle mit den Vor- und Nachteilen der verschiedenen Varianten zu sehen. Es gilt zu beachten, dass hier bei weitem nicht alle Punkte aufgelistet sind. Die Tabelle dient lediglich als kleine Zusammenfassung der wichtigsten Eigenschaften der drei Varianten.

Wie oben erwähnt, führen bei einer ML-Pipeline viele Wege zum Ziel. Im Folgenden ist ein beispielhafter ML-Workflow zu sehen. Der Workflow besteht lediglich aus Azure Produkten. Dies hat natürlich den Vorteil, dass die Konnektoren nahezu perfekt aufeinander abgestimmt sind.
Auch im Bereich des Machine Learning haben wir als arelium zahlreiche Kundenprojekte betreut. Darunter eine Machbarkeitsstudie zur Betrugserkennung mit dem Azure ML Studio. Hier haben wir zusammen mit dem Kunden eine auf ihr System maßgeschneiderte Lösung ausgearbeitet. Wenn wir Ihre Neugierde geweckt haben, kontaktieren Sie uns gerne. Wir helfen Ihnen zu verstehen, wie Sie die Technologie nutzen können und helfen bei der Implementierung.
Mehr Informationen zu diesem Thema, finden Sie auch auf unserem YouTube-Kanal.




