
Sommerloch in der IT: Wie Microsoft Fabric Licht in die Ressourcenplanung bringt
Sommerloch in der IT-Ressourcenplanung Wenn die halbe Firma am Strand liegt und die andere Hälfte Wunder vollbringen soll, beginnt in…

In einem vorherigen Beitrag hatten wir uns die grundlegenden Join-Typen in SQL angesehen. Doch es gibt noch weitaus mehr Möglichkeiten, SQL-Tabellen miteinander zu verknüpfen. Daher werfen wir hier einen Blick auf fortgeschrittene Join-Typen. Wir empfehlen Ihnen, zuerst den vorherigen Beitrag zu SQL-Joins zu lesen. Dort findet sich auch eine Beschreibung der Beispieldaten, die wir hier wieder aufgreifen.
Beim Anti-Join möchte man alle Einträge aus der linken/rechten Tabellen anzeigen, die nicht in der jeweils anderen Tabelle enthalten sind. Die andere Tabelle wird also nur als Filter gebraucht.
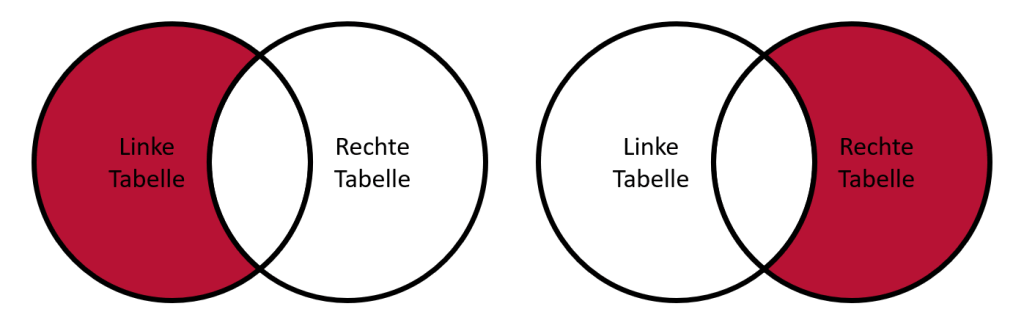
Dies kann zum Beispiel hilfreich sein, um in der Artikeltabelle Ladenhüter zu identifizieren, die nicht verkauft wurden. Dafür nutzen wir folgende Abfrage:
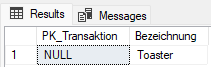
SELECT ft.[PK_Transaktion], da.[Bezeichnung] FROM [EinfacherHandel].[dbo].[FactTransaktionen] ft RIGHT OUTER JOIN [dbo].[DimArtikel] da ON ft.FK_Artikel = da.PK_Artikel WHERE ft.FK_Artikel IS NULL
Der Unterschied zum RIGHT OUTER JOIN ist also nur die letzte Zeile. Durch die WHERE-Klausel werden nur Artikel angezeigt, die in der Faktentabelle nicht enthalten sind. In dem Fall handelt es sich nur um den Toaster:
Der Self Join verknüpft eine Tabelle mit sich selbst. Dies wird oft gebraucht, wenn sich unterschiedliche Hierarchie-Stufen in einer Tabelle befinden. Ein beliebtes Beispiel ist hierbei eine Mitarbeiter-Tabelle, wobei für jeden Mitarbeiter in einer zusätzlichen Spalte die ID des Vorgesetzten angegeben wird. Verknüpft man jeweils den Primärschlüssel mit der ID des Vorgesetzten, kann man für jeden Mitarbeiter den Namen des Vorgesetzten anzeigen.
Wir wollen aber bei unserem Beispiel bleiben und einen Eindruck vermitteln, was mit dem Self Join noch möglich ist. Dazu stellen wir uns vor, dass unser Beispiel-Händler in einer fragwürdigen Rabatt-Aktion die Preise der Produkte aus der DimArtikel vertauschen will. Mit der folgenden Anweisung lässt sich jedem Artikel der Preis des jeweils vorherigen Artikels aus der Liste zuordnen:
SELECT da1.PK_Artikel, da1.Bezeichnung, da1.Preis [alter Preis], da2.Preis [neuer Preis] FROM [dbo].[DimArtikel] da1 LEFT OUTER JOIN [dbo].[DimArtikel] da2 ON da1.PK_Artikel = da2.PK_Artikel + 1
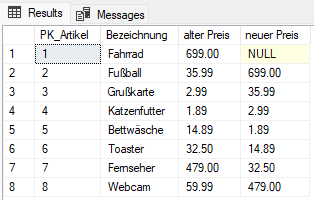
Dem Fahrrad lässt sich kein neuer Preis zuordnen, da es der erste Artikel in der Tabelle ist. Außerdem werden die Kunden vermutlich wenig Verständnis haben, wenn ein Fußball plötzlich 699€ kostet. Will man die Zuordnungen besser steuern, kann man eine zusätzliche Spalte anlegen, in die wir die passende ID schreiben. Dazu haben wir eine neue Tabelle DimArtikelPreise angelegt mit der Spalte TauschID. Wir erstellen folgende Abfrage:
SELECT da1.PK_Artikel, da1.Bezeichnung, da1.Preis [alter Preis], da1.TauschID, da2.Preis [neuer Preis] FROM [dbo].[DimArtikelPreise] da1 INNER JOIN [dbo].[DimArtikelPreise] da2 ON da1.TauschID = da2.PK_Artikel
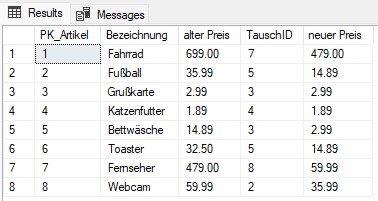
Nun sehen wir, dass wir mithilfe der Spalte „TauschID“ angeben können, welcher Preis aus der Artikel-Tabelle dem jeweiligen Artikel neu zugeordnet werden soll. Dies ist das gleiche Prinzip, als wenn wir für Mitarbeiter ihre Vorgesetzten angeben. Statt der Spalte „TauschID“ hätten wir hier dann die IDs der Vorgesetzten, und statt „neuer Preis“ hätten wir die Namen.
Fortgeschrittene Join-Typen haben einige Besonderheiten und das gilt auch für den Cross-Join. Bei diesem wird nicht nach passenden Schlüsseln gesucht, sondern es wird für jeden Eintrag aus der linken Tabelle jeder Eintrag aus der rechten aufgeführt. Die Zeilenzahl der Ergebnis-Tabelle entspricht also dem Produkt der Zeilenzahlen der Einzeltabellen. Den Cross-Join verwendet man in der Praxis eher selten. Bei relationalen Datenbanken würde man damit redundante Ergebnisse erzeugen.
Dennoch gibt es Beispiele, wo der Cross Join von Nutzen ist. Bei unserem Beispiel könnten wir uns vorstellen, dass jeder Artikel in verschiedenen Farben erhältlich ist, für die wir eine neue Tabelle DimArtikelfarbe_Faktor angelegt haben:
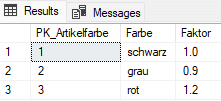
In der dritten Spalte geben wir einen Faktor an, über den wir den Preis anpassen wollen. Nun führen wir folgenden Cross Join aus:
SELECT da.PK_Artikel, da.Bezeichnung, daf.Farbe, da.Preis * daf.Faktor [Preis] FROM DimArtikel da CROSS JOIN DimArtikelfarbe_Faktor daf WHERE da. PK_Artikel NOT IN (3, 4, 7)
Da man jede Zeile mit jeder verknüpft, brauchen wir, im Gegensatz zu den anderen Join-Typen, keine ON-Klausel. Über eine WHERE-Klausel entfernen wir noch jene Artikel, für die die Farbauswahl wenig Sinn macht. Wir erhalten:
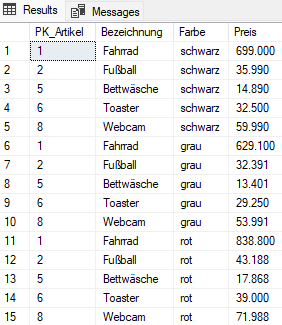
In der vierten Spalte sehen wir das Ergebnis der Multiplikation. Die Preise für die schwarzen Artikel sind die gleichen wie vorher, die grauen Artikel sind um 10% günstiger und dir roten um 20% teurer.
Die Erhöhung der Redundanz kann also durchaus gewollt sein, wenn wir eine detailliertere Ansicht wünschen. Auch der Cross-Join hat also seine Daseinsberechtigung, selbst in relationalen Datenbanken.
In diesem Beitrag haben wir fortgeschrittene Join-Typen kennengelernt und damit einen kleinen Einblick erhalten, was T-SQL für eine Vielzahl an Möglichkeiten bietet, um mit Daten zu arbeiten. Neben dem grundsätzlichen Aufbau haben wir am Beispiel des Self Join auch gesehen, dass sich Join-Bedingungen individuell verändern lassen. Darüber hinaus gibt es auch Fälle, in denen man mehrere Join-Bedingungen braucht, z.B. wenn die Tabellen keine eindeutige Schlüsselspalte haben. Während für einfache Abfragen meist die grundlegenden SQL-Joins ausreichen, sind die fortgeschrittenen SQL-Joins für anspruchsvollere Analysen sowie zur Datenbank-Entwicklung ein sehr mächtiges Werkzeug, sowohl on-premise als auch mit Azure SQL.




